
Unterliegt ständiger Änderung
So sieht die URL aus, am oberen Rand eines jeden Browsers zu finden;
ein langes leeres Feld zur Eingabe eines Begriffes, eines Namens, eines Zeigers auf eine einmalige Information im Internet.
Hier das dunkel umrahmte gelbe Feld des Browsers. Dort steht schon
'Mit Google suchen oder Adresse eingeben'



Dieses *oder* macht uns auf DAS Geheimnis hinter diesem Feld aufmerksam.
Es kann nämlich eine Adresse, also eine URL, ein Link direkt auf die Information eingeben werden - oder ein Suchbegriff, nachdem eine Information gesucht werden soll.
Bei einem Suchbegriff (hier unten 'bl') kommen schon während der Eingabe gefundene Einträge. Hinter diesen Einträgen verbergen sich URLs, also Zeiger zu diesen Informationen. Ein Klick darauf - und schon wird die Information gezeigt. Einfacher gehts doch wirklich nicht.
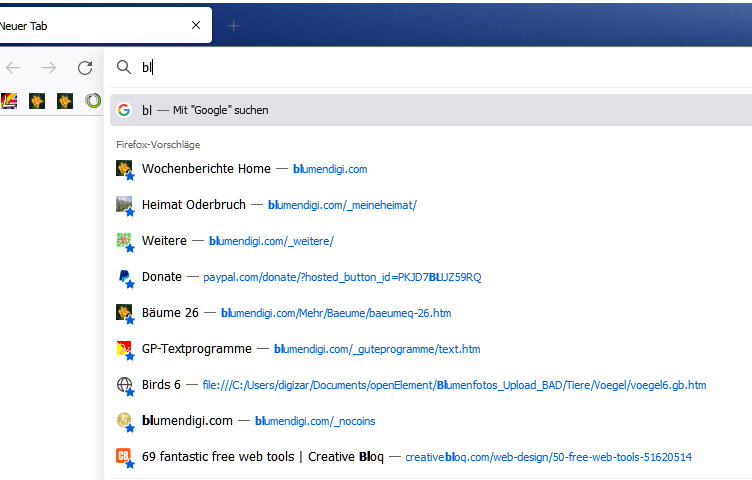
Dabei kommen 'Google' von Google oder 'Bing' von Microsoft als aktive Suchmaschinen zum Zuge. Diese durchsuchen innerhalb einiger Sekunden ihre bereits gesammelten Werke, nämlich das was sie im Internet gefunden haben. Deshalb durchsuchen sie das gesamte Internet ständig, und speichern die Funde als URLs, als Link zu diesen gefundenen Informationen in einer oder mehreren internen riesigen und schnellen DatenbankTabellen ab.
Ähnlich einem Buch, für das ein Inhaltsverzeichnis erstellt wird.
Nicht die Information wird katalogisiert; denn diese steht ja am OriginalPlatz, wohin der Link -des Inhaltsverzeichnisses- weist. Und es würde keinen Sinn machen, die Information doppelt zu speichern, weil die OriginalInformation geändert werden könnte. Der Zeiger, die URL, der Link darauf ändert sich nicht, oder nur ganz selten.
Wird diese Information aber entfernt, die Seite also aus dem Buch gerissen, dann bleibt der Link des Inhaltsverzeichisses darauf dennoch bestehen. Der Leser des Buches sieht dann dort keine Seite, im Internet den Hinweis '...nicht gefunden'.
Suchmaschinen durchsuchen ständig das Internet; stoßen sie dabei auf nicht mehr vorhandene Information, dann nehmen sie oft, jedoch nicht immer, auch den unnötigen Link darauf aus ihrem Verzeichnis. Somit wird diese Information auch nicht mehr angeboten. Den Link, die URL dorthin gibt es also auch nicht mehr; die Webseite ist normalerweise verschwunden.
Sie muss aber nicht wirklich verschwunden sein; sie kann noch existieren, kann nur nicht gefunden werden. Ist aber die Stelle bekannt, bei der sie mal zu finden war, dient der Link, die URL dazu, direkt darauf zuzugreifen. Nur Suchmaschinen -als Inhaltsverzeichnis- kennen sie nicht mehr.
Was von Suchmaschinen gefunden werden soll und darf, liegt beim Ersteller einer jeden Webseite, beim sogenannten SEO. Aber das ist ein ganz anderes, doch recht trickreiches Thema.
Diese Suchmaschinen zeigen zu dem URL/Link auch einen Teil, einen Ansatz der gefundenen Informationen, damit wir uns aussuchen können, welcher von ähnlichen Funden unserer Vorstellung am ehesten entspricht.
Aber was der HauptSinn der Suche ist, sie zeigt den Link, die Adresse, eben diese URL,
wo diese Information genau zu finden ist.
Ohne diese Adresse, ohne diesen Link wären das Internet mit den Suchmaschinen ziemlich nutzlos; denn wer findet manuell eine bestimmte Information im weltweiten Internet.
Diese Arbeit nehmen einem diese Suchmaschinen ab, indem sie uns eine URL, einen Link zu solcher Information bringen.
Da hatte Google eine wirklich gigantisch gute Idee - und wurde deshalb riesengroß und unvorstellbar reich.
So viel zum ersten Sinn der URL.
Aber dahinter verbirgt sich mehr.
Und zwar der Fall, wenn eine bestimmte URL eingegeben wird, weil deren Name bekannt ist, Oder von Werbetreibenden schon geliefert wird.
Oder wenn ich zB auf meine anderen Webseiten hinweise. Da braucht ja keiner mehr zu suchen, kann das aber immer noch machen.
Das Geheinmis liegt bei der Art des in der URL-Zeile eingebenen Begriffes. Auch das ist ganz einfach.
Es geht weiter bei *Was damit anfangen*
ein langes leeres Feld zur Eingabe eines Begriffes, eines Namens, eines Zeigers auf eine einmalige Information im Internet.
Hier das dunkel umrahmte gelbe Feld des Browsers. Dort steht schon
'Mit Google suchen oder Adresse eingeben'
Dieses *oder* macht uns auf DAS Geheimnis hinter diesem Feld aufmerksam.
Es kann nämlich eine Adresse, also eine URL, ein Link direkt auf die Information eingeben werden - oder ein Suchbegriff, nachdem eine Information gesucht werden soll.
Bei einem Suchbegriff (hier unten 'bl') kommen schon während der Eingabe gefundene Einträge. Hinter diesen Einträgen verbergen sich URLs, also Zeiger zu diesen Informationen. Ein Klick darauf - und schon wird die Information gezeigt. Einfacher gehts doch wirklich nicht.
Dabei kommen 'Google' von Google oder 'Bing' von Microsoft als aktive Suchmaschinen zum Zuge. Diese durchsuchen innerhalb einiger Sekunden ihre bereits gesammelten Werke, nämlich das was sie im Internet gefunden haben. Deshalb durchsuchen sie das gesamte Internet ständig, und speichern die Funde als URLs, als Link zu diesen gefundenen Informationen in einer oder mehreren internen riesigen und schnellen DatenbankTabellen ab.
Ähnlich einem Buch, für das ein Inhaltsverzeichnis erstellt wird.
Nicht die Information wird katalogisiert; denn diese steht ja am OriginalPlatz, wohin der Link -des Inhaltsverzeichnisses- weist. Und es würde keinen Sinn machen, die Information doppelt zu speichern, weil die OriginalInformation geändert werden könnte. Der Zeiger, die URL, der Link darauf ändert sich nicht, oder nur ganz selten.
Wird diese Information aber entfernt, die Seite also aus dem Buch gerissen, dann bleibt der Link des Inhaltsverzeichisses darauf dennoch bestehen. Der Leser des Buches sieht dann dort keine Seite, im Internet den Hinweis '...nicht gefunden'.
Suchmaschinen durchsuchen ständig das Internet; stoßen sie dabei auf nicht mehr vorhandene Information, dann nehmen sie oft, jedoch nicht immer, auch den unnötigen Link darauf aus ihrem Verzeichnis. Somit wird diese Information auch nicht mehr angeboten. Den Link, die URL dorthin gibt es also auch nicht mehr; die Webseite ist normalerweise verschwunden.
Sie muss aber nicht wirklich verschwunden sein; sie kann noch existieren, kann nur nicht gefunden werden. Ist aber die Stelle bekannt, bei der sie mal zu finden war, dient der Link, die URL dazu, direkt darauf zuzugreifen. Nur Suchmaschinen -als Inhaltsverzeichnis- kennen sie nicht mehr.
Was von Suchmaschinen gefunden werden soll und darf, liegt beim Ersteller einer jeden Webseite, beim sogenannten SEO. Aber das ist ein ganz anderes, doch recht trickreiches Thema.
Diese Suchmaschinen zeigen zu dem URL/Link auch einen Teil, einen Ansatz der gefundenen Informationen, damit wir uns aussuchen können, welcher von ähnlichen Funden unserer Vorstellung am ehesten entspricht.
Aber was der HauptSinn der Suche ist, sie zeigt den Link, die Adresse, eben diese URL,
wo diese Information genau zu finden ist.
Ohne diese Adresse, ohne diesen Link wären das Internet mit den Suchmaschinen ziemlich nutzlos; denn wer findet manuell eine bestimmte Information im weltweiten Internet.
Diese Arbeit nehmen einem diese Suchmaschinen ab, indem sie uns eine URL, einen Link zu solcher Information bringen.
Da hatte Google eine wirklich gigantisch gute Idee - und wurde deshalb riesengroß und unvorstellbar reich.
So viel zum ersten Sinn der URL.
Aber dahinter verbirgt sich mehr.
Und zwar der Fall, wenn eine bestimmte URL eingegeben wird, weil deren Name bekannt ist, Oder von Werbetreibenden schon geliefert wird.
Oder wenn ich zB auf meine anderen Webseiten hinweise. Da braucht ja keiner mehr zu suchen, kann das aber immer noch machen.
Das Geheinmis liegt bei der Art des in der URL-Zeile eingebenen Begriffes. Auch das ist ganz einfach.
Es geht weiter bei *Was damit anfangen*